

Response to Dynomight on Scribble-based Forecasting
When is mathematical modeling helpful for making predictions?

Dynomight asks this question while thinking about the complicated models that AI 2027 used to project timelines. We don’t really understand the precise forces that are leading to longer time horizons, and there are much simpler ways to fit a curve. Why would we even think such a highly parameterized modeling exercise would be useful?
Us Spockish types are naturally drawn toward building explicit models of the world. But people are confused about how to do it right, leading them to regularly invest ungodly effort into building useless models. When is mathematical forecasting useful and when is it horribly misguided? Dynomight offers a two-pronged tests for recognizing purposeful models:
It evolves according to some well-understood rule-set.
The behavior of the ruleset is relatively complex.
I love the idea of a test for identifying useful modeling efforts, but I disagree with both of Dynomight’s suggested prongs.
Contra Prong #1. You actually can build great forecasts even when you don’t understand the rules. This is basically how unsupervised machine learning operates, where algorithms find patterns in the data that were not prospectively understood by researchers. For example, my earlier linked example of a “useful model” was Youyang Gu’s pandemic forecast, which used machine learning to kick ass predicting COVID-19 mortality, while ignoring most of what epidemiologists thought they understood about disease modeling.
Contra Prong #2. Often, models will perform best when the underlying rules are actually very simple. So a model that forecasts the acceleration of falling objects at 9.8 meters per second per second will out-perform scribble forecasts, despite being a very simple idea.
What are some better prongs? I’ll appeal to two books on meta-forecasting: Signal and the Noise and Superforecasting.
Silver View. Signal and the Noise takes an outside-view on the usefulness of mathematical prediction. Chapter-by-chapter, he runs through different domains, evaluating how useful forecasting techniques are for elections, sports, weather, earthquakes, economic growth, pandemics, and climate change. A clear pattern in Silver’s research is that forecasting models work best when you are making prospective predictions on a stable statistical process that is generating lots of data on an ongoing basis. This gives you a lot of historical data that you can use to fit a model, forces you to predict out-of-sample, punishes you when your model sucks, and enables you to iteratively calibrate toward better models. This is why we have increasingly great models for predicting daily weather, local elections, and sports. But we struggle to predict patterns for novel pandemics, the timing of recessions, or kinks in the long-run climate trends.
Dynomight uses climate science modeling as his case study of where complex mathematical modeling is appropriate. Yet, scribbling does great for multi-decade climate forecasting. In the below chart, I covered half the picture with my hand, scribbled a line, and it lined up pretty well with the global temperature record.
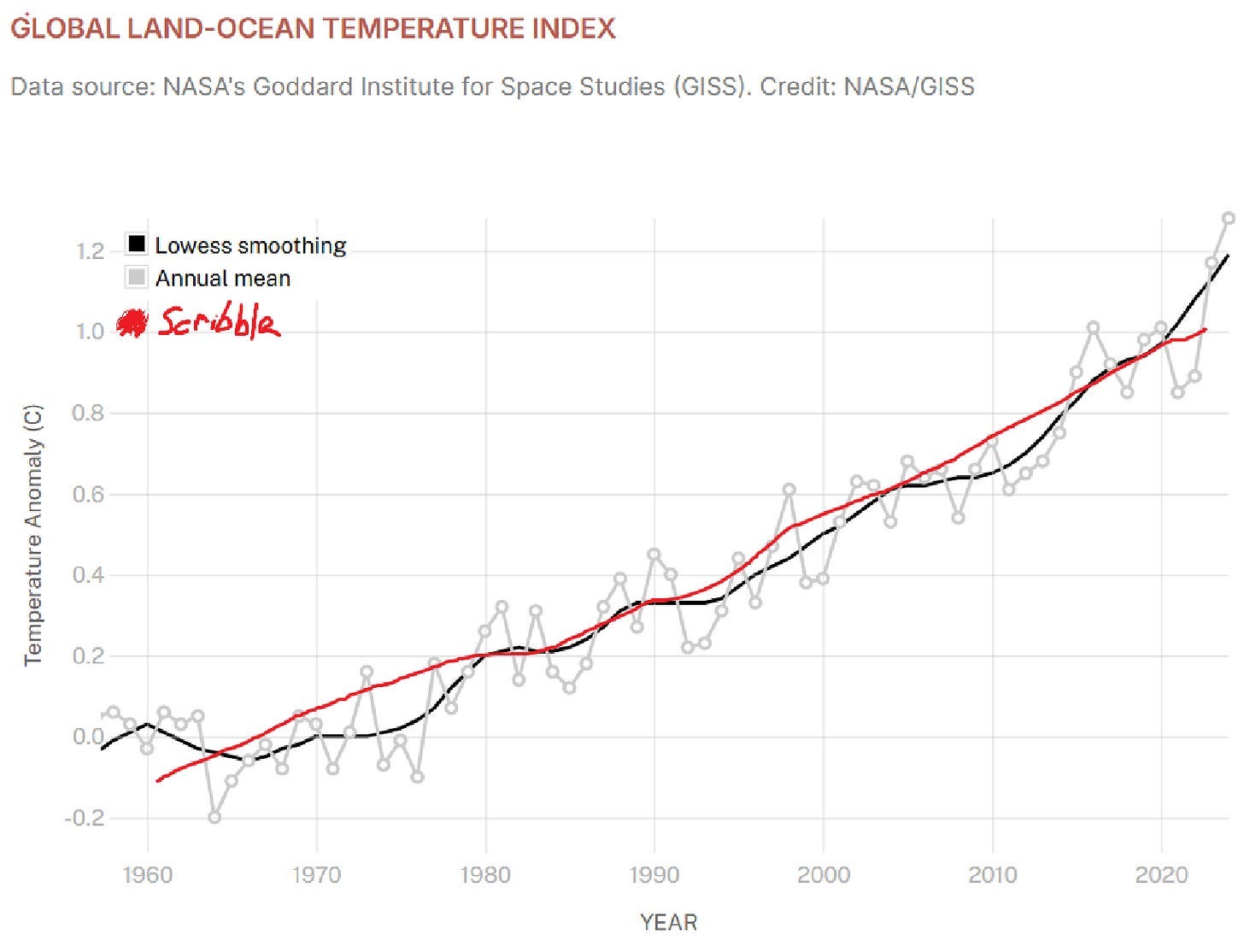
That’s because global temperature has actually been stably increasing by 0.2 degrees Celsius per decade for the last 60 years. Looking forward, if I assume temperatures continue to increase 0.2 degrees per decade, that projection puts me inside the 75th percentile range for the Metaculus community projection, albeit lower than their median.
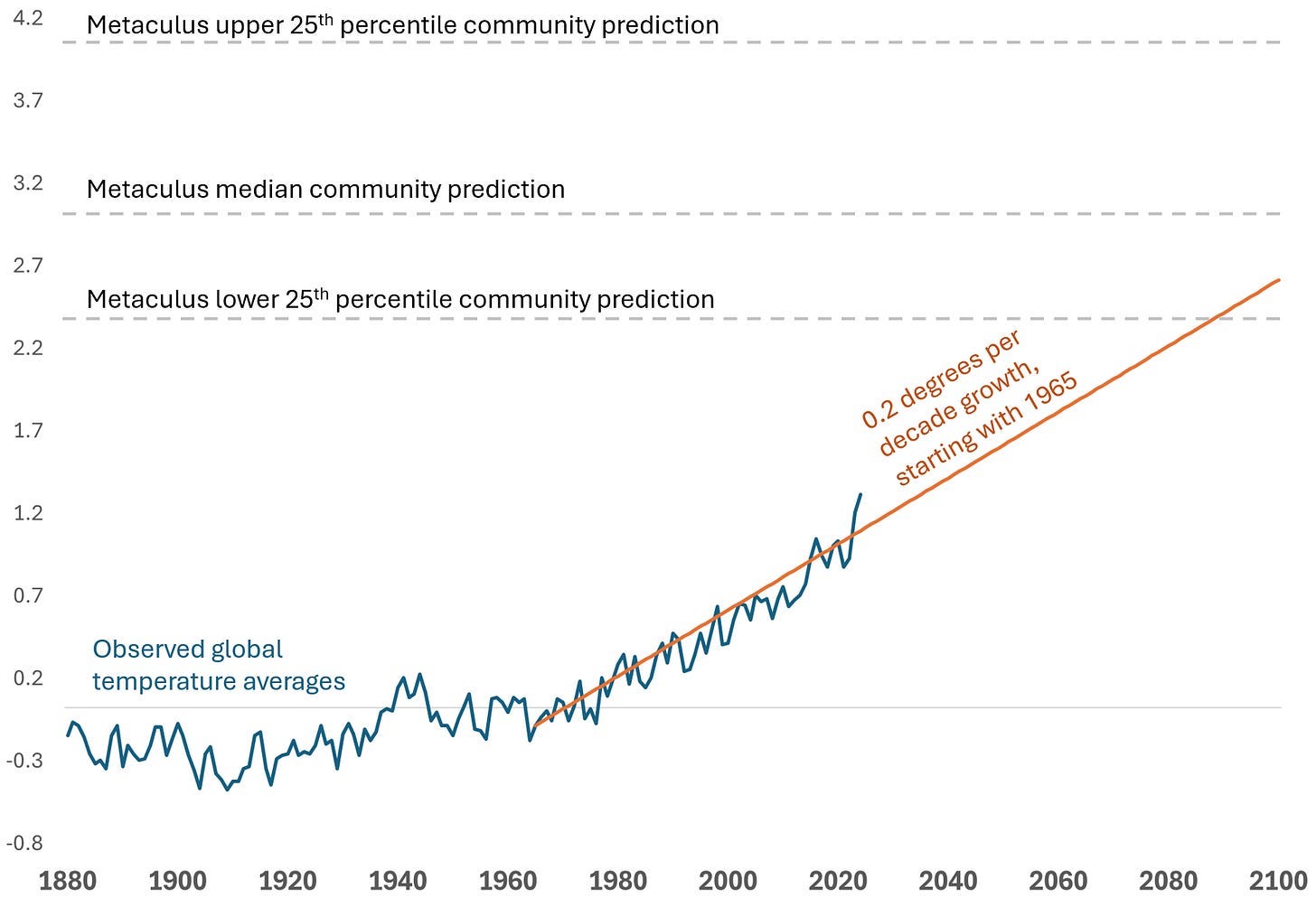
Again, the challenge with climate modeling is that global temperature data is so noisy, that you only get a real data point every decade. If you try to update after just a few years, you get confused. It might feel like the climate models are becoming more sophisticated, but since we’ve been on a simple linear trend for the last 60 years, it’s hard to know what that sophistication amounts to. And these models generally don’t predict short-term fluctuations well, like the warming slowdown in the 1990s or the warming speedup in the 2020s.
Tetlock-Gardner view. The idea of Superforecasting was to study people who have great prediction track records and try to understand their characteristics and their process. The famous finding is the distinction between the hedgehogs and the foxes, where hedgehogs know one big thing (e.g. the “first principles” Elon Musk types) and the foxes knows many little things (e.g. the “resourceful, frequent updater” Nate Silver types). Empirically, the foxes make for good predictors and the hedgehogs make for bad ones.
Is building a complicated mathematical model something a fox would do or a hedgehog would do? It’s probably more of a fox thing, but there is also hedgehog style of model building. The hedgehog modeler identifies a particular way of looking at a problem, and tries to simulate that dynamic in detail. Their frameworks will become increasingly complex, as they refine their model to more precisely capture the particular aspect of the problem that they chose to focus on. They will view the results from their model as the best possible answer, and if you disagree, they will say “what specific part of my model do you disagree with?”
Yet, their approach has issues. Their clunky models are harder to update with new data or to integrate with alternative ways of looking at the problem. Their models go deep and are complex, which makes it difficult for others to helpfully engage with them. And they are emotionally invested in their models, which leads them to respond to new evidence by adapting their framework, rather than down-weight its credence.
Foxes will also rely on mathematical models, but they will tend to use lots of them. Some of the models might be akin to Dynomight’s scribbles and sometimes they might be more complicated. The more complicated models will tend to develop iteratively, where they adopt incremental changes that improve performance. And the fox’s final answer won’t typically be the output of any one model, but rather a highly messy subjective weighting of the available evidence, where they constantly rejigger the weights in response to new information.
Is the AI 2027 approach more fox or hedgehog? Most annoying answer possible… it’s a mix. Their modeling was over-engineered and too confident in certain core beliefs, such that the pace of AI progress will inevitably accelerate. But the team also does a lot of foxy stuff. They built multiple models and averaged them. They dug into the details and made their thinking easy to understand. And they incorporated perspectives from people with excellent forecasting track records.
Most people use models badly. They are too deferential before-the-fact and too dismissive after-the-fact. Lots of good models make bad predictions, and the model-builders are often aware of this. You should think of more speculative models as just tools for thinking systematically, rather than thinking of them as incompetent oracles. Speculative models are like philosophical thought experiments, where you say “if you make these intuitive assumptions, what does that imply?” This helps you establish priors, weigh evidence, make discoveries, and communicate your thinking.
This is one of the strongest features of the AI 2027 research. They made their thinking legible, which lets us have a disciplined conversation, identify disagreements, and make progress. Even if we reject their predictions, we should appreciate the structure they have given to the problem. In this way, their work is unambiguously excellent.
So when do I think you should you pull your prediction directly from a mathematical model? The clearest case is when you have a validated model that has a track record of successful predictions, as we have in the case of daily weather forecasting. That’s a frustrating answer, because it might feel like for a lot of problems, no such model will exist. That’s increasingly less true, because we have reputation-based prediction markets, like the Metaculus Community Prediction, which you can think of as a validated mathematical model that will answer basically any question you ask of it. For forecasting, just asking Metaculus will out-perform most other strategies you can come up with.
The best Metaculus predictors will rely on mathematical models, even when it’s for a process they don’t understand well or when there are only simple dynamics at play. They’ll use validated models when available, but they’ll also rely on shitty back-of-the-envelopes and flawed quantitative analogies. They won’t just blindly go with whatever the model spits out. The model will be just one more data point they synthesize with everything else they know, constantly questioning, and constantly iterating. As is the way of the fox.
Edits: The temperature trajectory has been stable for ~60 years, not ~80 years as I originally wrote.
This is a great post. My only quibble is that I didn't mean to suggest that the two prongs are *necessary* for math-based forecasts to be useful, but just that math-based forecasts tend to be more useful to the degree they are true.
In principle, I think math-based forecasts are basically always better. (In some sense, math-based forecasts are a strictly larger set.) It's mostly that the *difficulty* of creating a math-based forecast that doesn't add some dubious assumptions increases when the rule-set is harder to understand, and the benefit of math-based forecast tends to be lower when the behavior of the ruleset is less.
So I agree with most of what you say here. I particularly endorse the point you make in your last paragraph, that even an ultra-simplified math-based forecast is useful as a sort of "input" to human intuition. I think that's an important point that I basically totally failed to make in my post!